Introduction
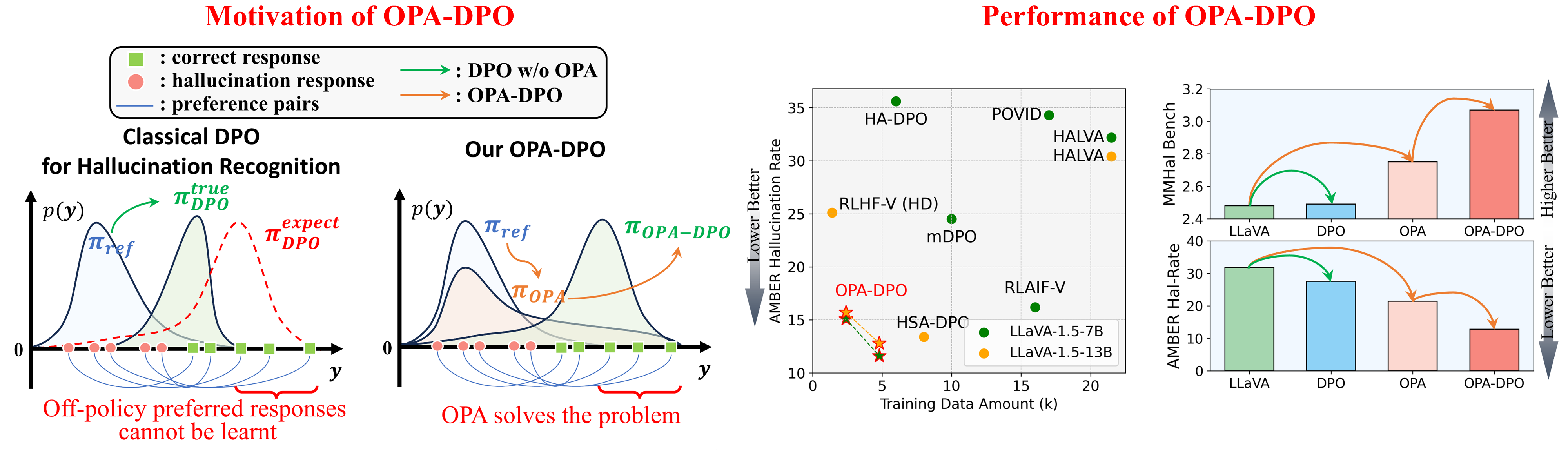
Motivation and Performance Summary:
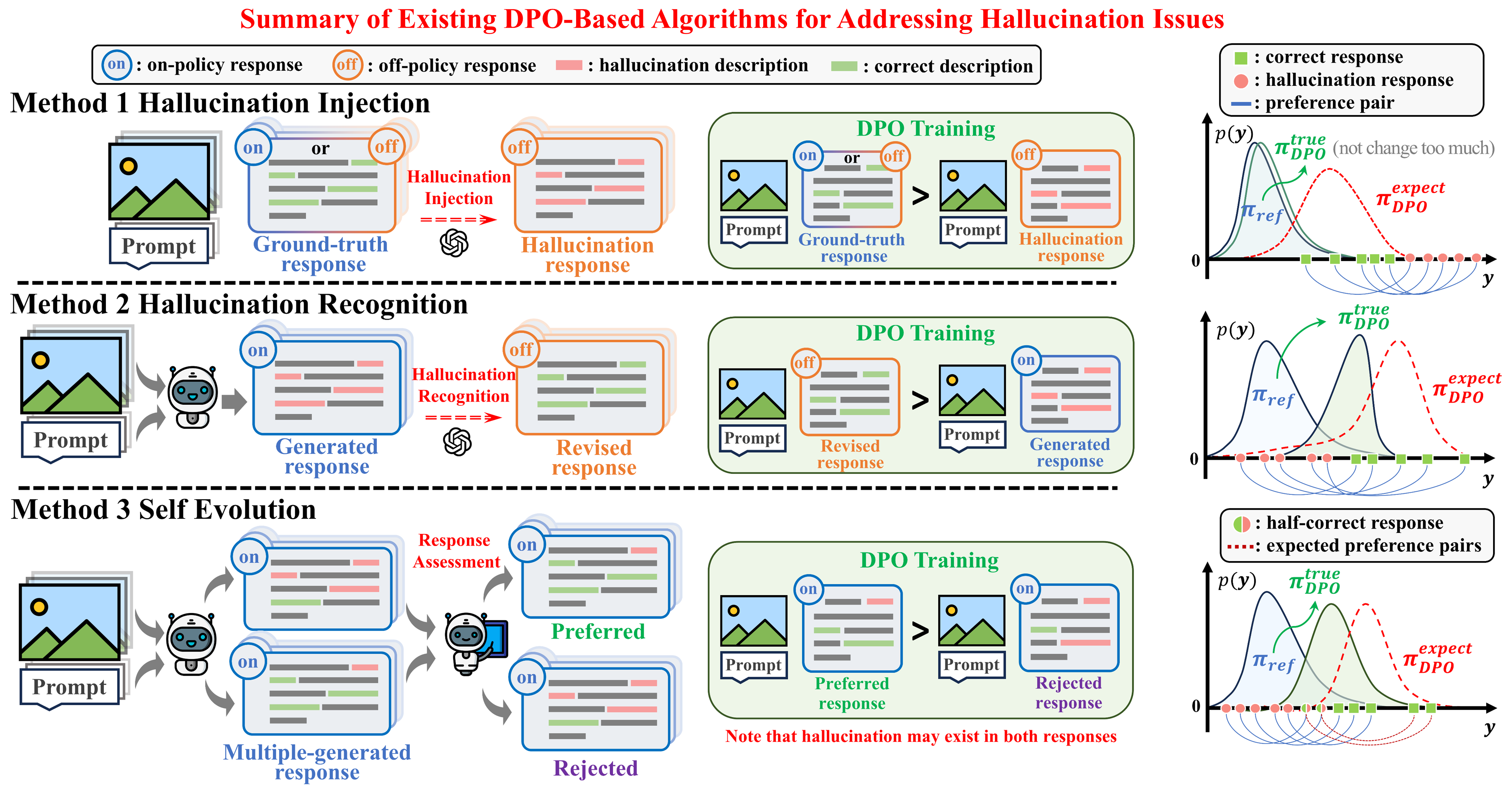
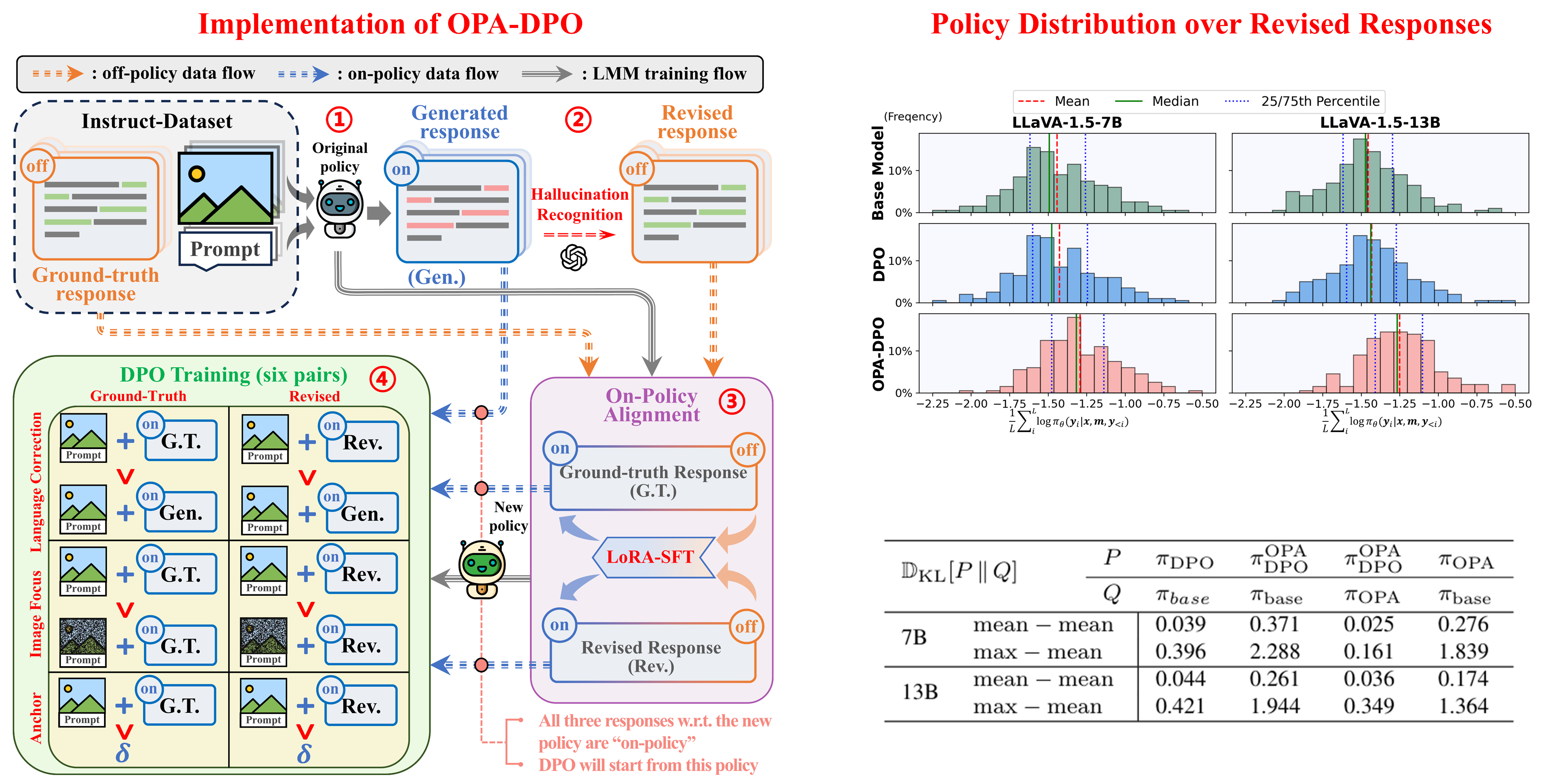
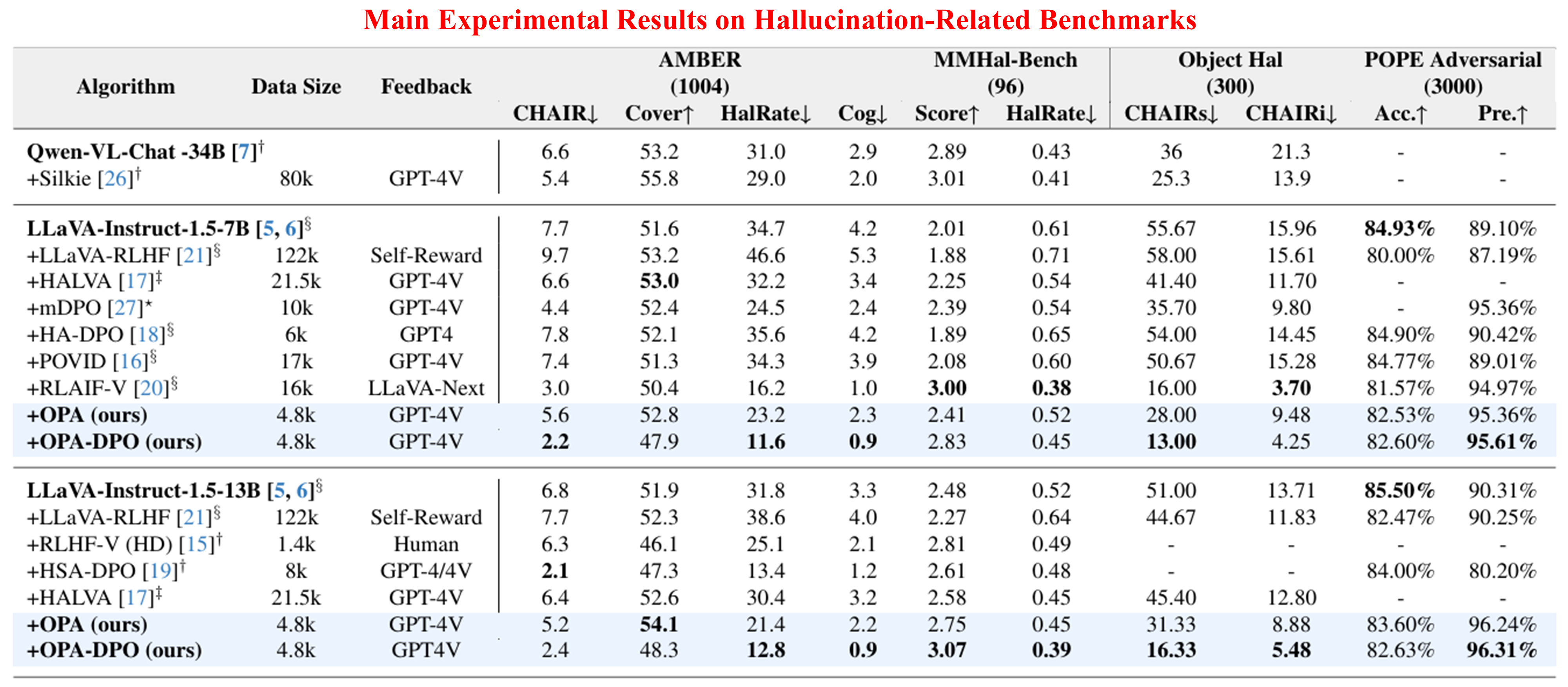
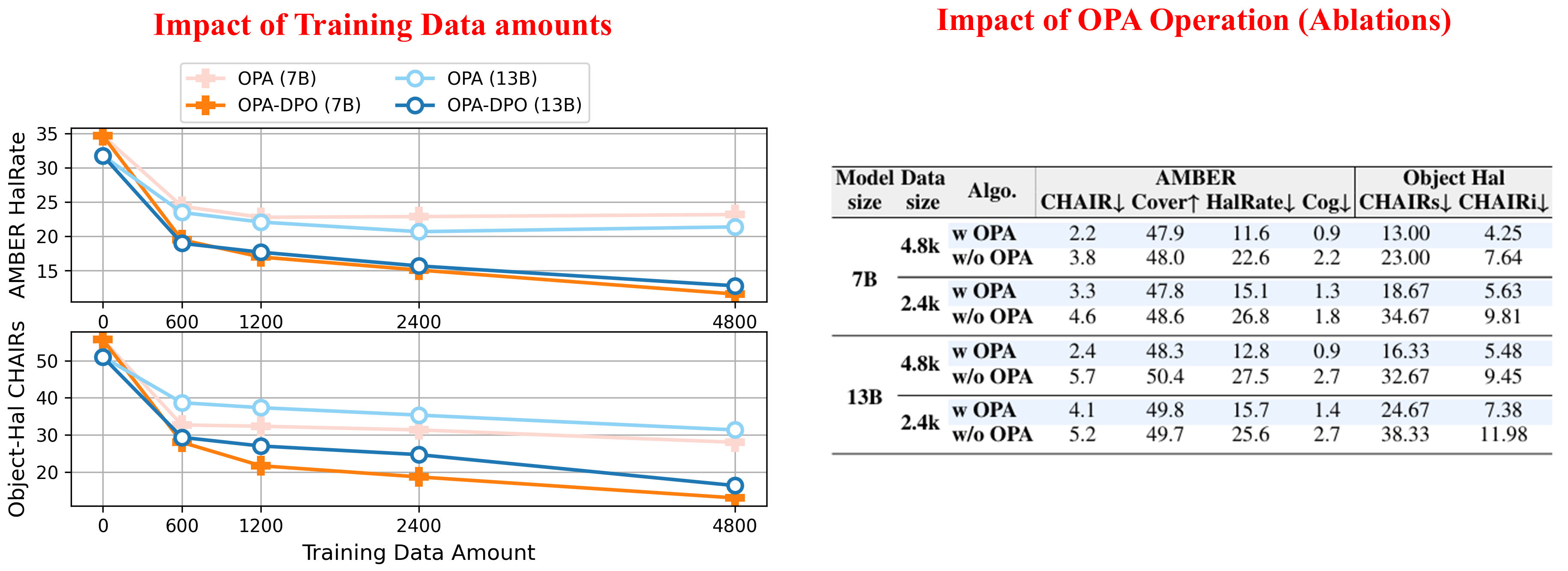
To mitigate hallucinations in LVLMs (or MLLMs) with DPO, the most effective approach would be to have the model generate a response based on a given prompt and image, followed by experts correcting hallucinations in the generated content to construct preference pairs. However, in practice, even when these corrections are minor, the corrected responses are often off-policy relative to the original model (i.e., they have extremely low sampling probabilities). We reveal a key point that are often neglected in existing works: the off-policy prefferred response can NEVER be learnt by the models due to the implicit KL constraints. Based on this observation, we propose OPA-DPO, which aligns the constructed data on-policy before DPO training. Experimental results demonstrate that OPA-DPO significantly improves performance by incorporating the OPA operation and achieves SOTA results with minimal data requirements.
Demo of Kullback-Leibler (KL) Divergence:
Noticed that the initial training objective of DPO is to maximize the reward-model induced by Bradley-Terry model, while constraining the KL divergence between the model and the reference policy. To provide an intuitive understanding of the importance of on-policy data, we visualize the KL divergence between the current policy (\(\,\pi_\theta\,\)) and the reference policy (\(\,\pi_{ref}\,\)). You can drag the sliders to adjust the mean and variance of the current policy, and observe how the KL divergence changes accordingly. In summary, the KL divergence becomes substantially large if the current policy generates tokens that the reference policy never produces.